Gestion des coûts Databricks


Cet article a été initialement publié sur tech.jolimoi.com à l’occasion d’une conférence que nous avons donnée lors d’un meetup Databricks, où nous étions invités à partager notre retour d’expérience sur la gestion de nos coûts.
Bien que le titre de cet article soit explicite, je précise que nous ne parlerons pas d’optimisation de code.
Les coûts peuvent certes être liés à la performance (comme l’implémentation de modèles et l’optimisation du stockage), mais ce sujet est suffisamment vaste pour mériter des articles dédiés.
Cet article couvrira en revanche la plupart des bonnes pratiques en matière de gestion et de maîtrise des coûts Databricks. Un sujet après l’autre.
Un peu de contexte
Chaque entreprise a sa propre vision de ses dépenses, notamment sur les plateformes cloud, et Databricks ne fait pas exception.
Mais je préfère être, une fois de plus, transparent sur la manière dont nous utilisions Databricks chez Jolimoi :
- Nous avons un budget limité, projets R&D inclus
- En tant que startup, nous ne pouvons pas nous permettre de gaspiller des ressources sans justification. Notre budget est basé sur un pourcentage fixe, mais toujours ajusté chaque mois en fonction du chiffre d’affaires passé, ce qui signifie aucune marge de manœuvre
- Nous utilisions principalement Databricks pour l’ETL et le warehousing (
pip install dbt-databricks) - Nous sommes sur AWS
- Nous ne gérons pas des pétaoctets
Comprendre la structure des coûts
Cela semble évident, mais commençons par comprendre les composantes de nos dépenses. Pour cela, nous pouvons nous référer à quelques bonnes ressources, notamment :
- Prix publics
- Calculateur de prix
- Documentation Databricks sur l’optimisation des coûts
- Bonnes pratiques de gestion des coûts
- Paramètres du compte et utilisation
Contrairement à certaines solutions, les prix de Databricks semblent plus complexes. Principalement parce qu’ils se composent de deux parties :
- Les coûts cloud (AWS pour nous) soit : principalement le transfert de données, le compute et le stockage
- La consommation Databricks, une sorte de licence appelée DBU (DataBricks Units). Ce coût suit principalement le compute que vous mettez en face (plus le cluster/serveur/… est gros, plus vous payez). C’est un coût au temps consommé (à la seconde pour être précis)
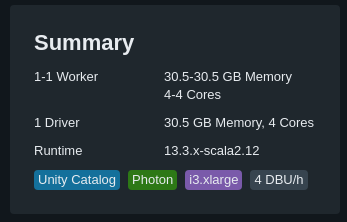
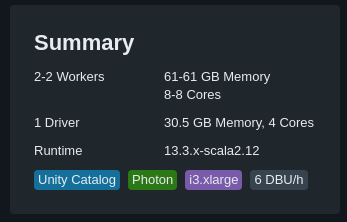
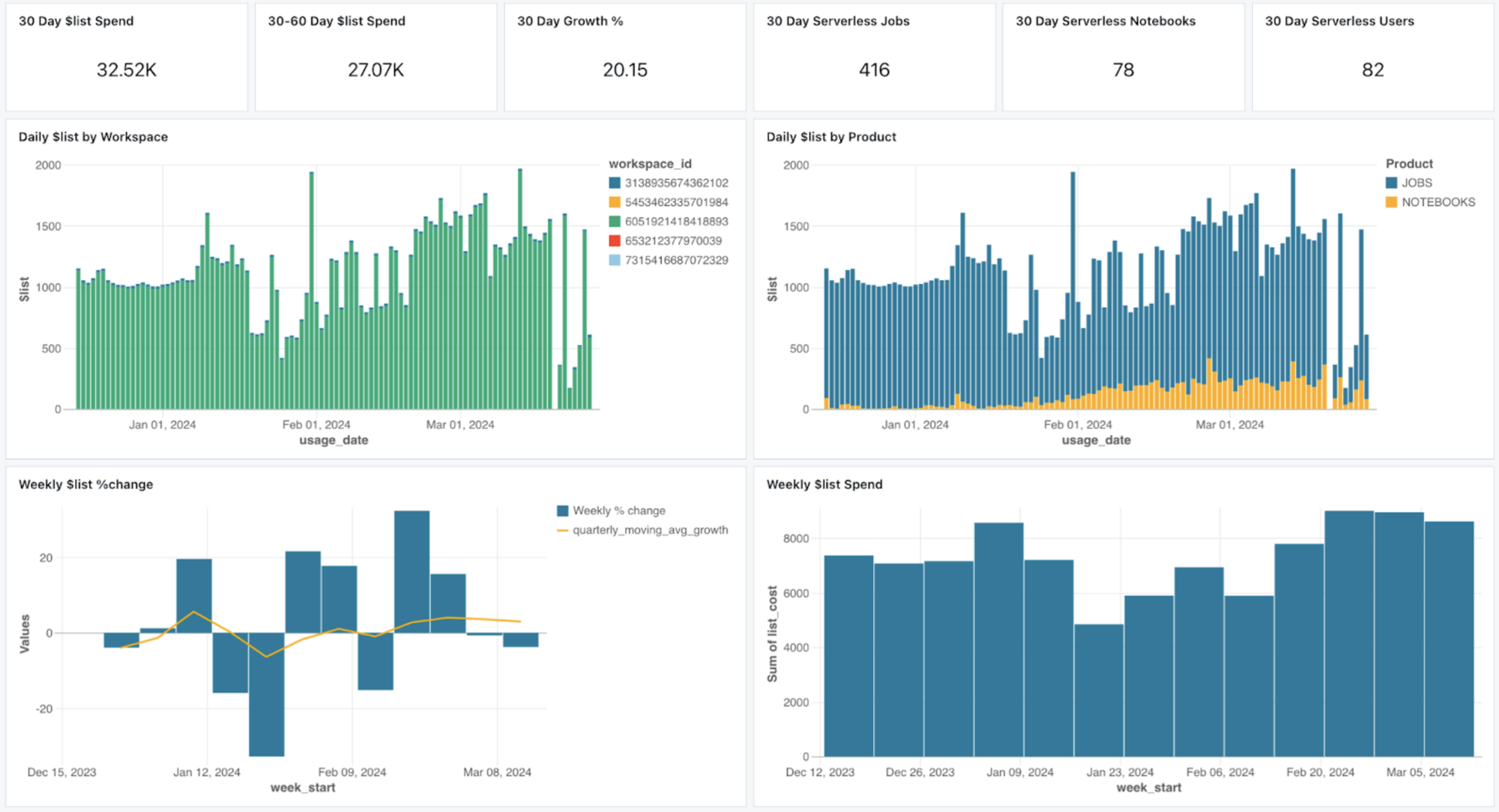
Vous pouvez observer une corrélation nette entre le nombre d’instances et les DBU consommées (dans cet exemple, 1 instance = 2 DBU/h)
Surveillez ce que vous payez (et taggez)
Maintenant que vous savez comment la facture sera répartie…
Pour cela, vous avez plusieurs options, mais la première que vous utiliserez est sans doute la console du compte. Elle permet de filtrer vos données d’utilisation à l’aide de divers graphiques. Ce filtrage peut se faire par : SKU, workspace et tags.
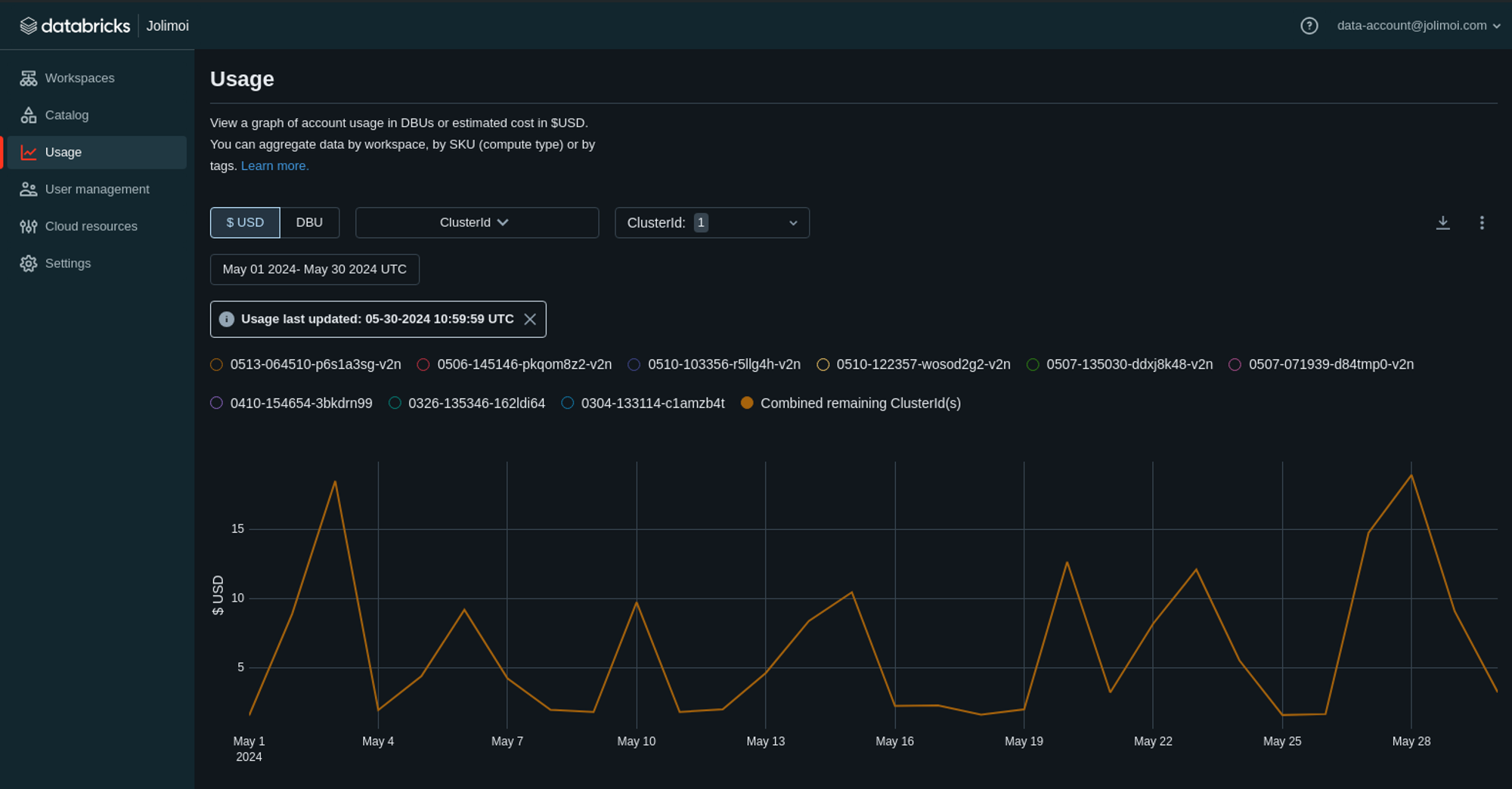
Même si cela ne fournit pas une analyse précise des coûts, c’est efficace dans un premier temps si vos tags sont bien configurés. Car oui, le tagging est une pratique classique mais toujours pertinente en matière de FinOps et de suivi des coûts.
Dans Databricks, certains tags sont configurés par défaut. Mais vous pouvez aussi définir votre propre convention de tagging. Chez Jolimoi, tous nos assets cloud (y compris Databricks, sauf les endpoints qui n’acceptaient pas les deux-points) sont configurés avec les tags suivants :
| Tag | Signification |
|---|---|
jm:application |
Le plus basique. Appelez-le feature ou autre chose comme projet, c’est l’identifiant clé concernant l’usage de cet asset |
jm:domain |
Peut être une division, une équipe ou simplement un domaine métier (marketing, data, etc.) |
jm:role |
Exemple : front, back, sécurité, ETL, data science |
jm:environment |
Production, Intégration, Staging, Sandbox… |
jm:owner |
Partie prenante clé, propriétaire du projet, analyste ou même un contact technique. En fait tout ce dont vous avez besoin pour identifier qui est responsable de cet asset en termes de facturation |
jm:managedBy |
Principalement pour identifier comment cet asset a été construit. Dans notre cas, cela peut être Terraform, CloudFormation ou tout simplement rien, ce qui signifie que c’était fait à la main |
jm:taggingVersion |
Même les conventions de tagging peuvent avoir des versions |
Ces tags ne sont pas uniquement intéressants pour comprendre qui utilise quoi (et avoir des informations plus lisibles qu’un ID de cluster). Ils sont pratiques pour appliquer des stratégies de show-back et charge-back vers d’autres entités métier, surtout si le budget IT est réparti dans l’entreprise.
Et pour reparler des données d’utilisation, elles sont disponibles via plusieurs canaux :
- API
- Livraison S3 (preview)
- Tables système (preview également, voir ci-dessous)
system.billing.usage
Et justement, concernant cette dernière option, si vous souhaitez exploiter ces données plus finement, vous devez utiliser les tables système.
Les tables système incluent :
system.billing.usage: Données d’utilisationsystem.billing.list_prices: Données de tarification des SKU Databricks à des moments précis
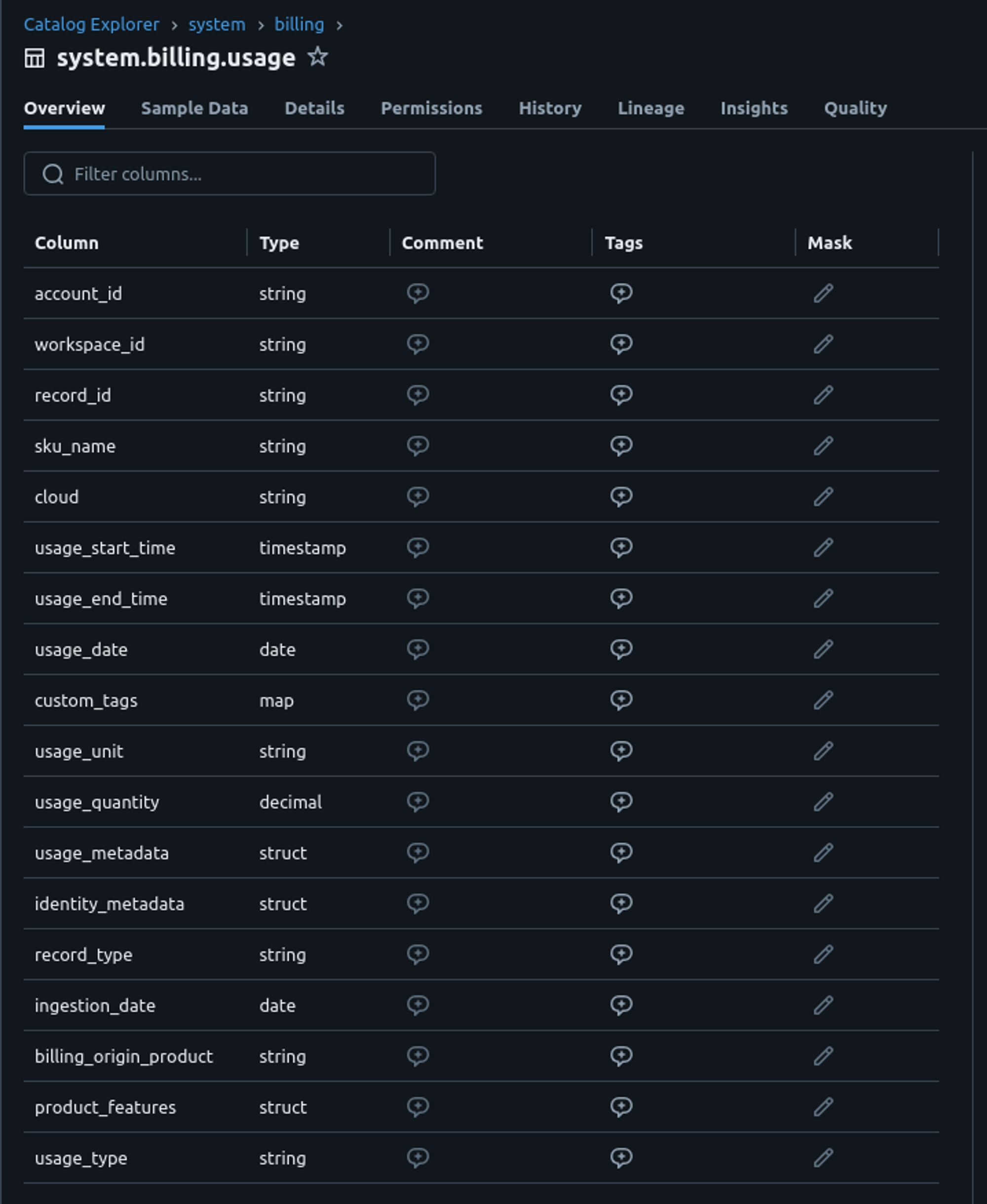
Si vous voulez jouer avec ces tables, Databricks met à disposition une liste d’exemples de requêtes et de templates.
Cependant, vous préférerez peut-être créer votre propre requête, comme celle-ci :
SELECT
billing_origin_product
, usage_date
, usage.sku_name
, COUNT(usage_quantity) as dbu_count
, CAST(pricing["default"] AS FLOAT) as pricing
, (dbu_count * CAST(pricing["default"] AS FLOAT)) as total_price
, custom_tags["jm:application"] as application
FROM system.billing.usage
INNER JOIN system.billing.list_prices on usage.cloud = list_prices.cloud
and usage.sku_name = list_prices.sku_name
and usage.usage_start_time >= list_prices.price_start_time
and (
usage.usage_end_time <= list_prices.price_end_time
or list_prices.price_end_time is null
)
GROUP BY
billing_origin_product
, usage_date
, usage.sku_name
, pricing["default"]
, custom_tags["jm:application"]
ORDER BY
usage_date DESC
, dbu_count DESC;
Ou encore le tableau de bord d’observabilité des coûts disponible sur Github (qui ne fonctionne pas très bien, et d’ailleurs pourquoi ne pas le mettre dans la galerie d’exemples ?).
Optimisez votre compute
Passons maintenant au sujet du compute et de ce qui peut être fait côté cloud. Puisque chaque option peut être liée à vos cas d’usage spécifiques, je me concentrerai principalement sur quelques recommandations générales concernant ce vaste sujet.
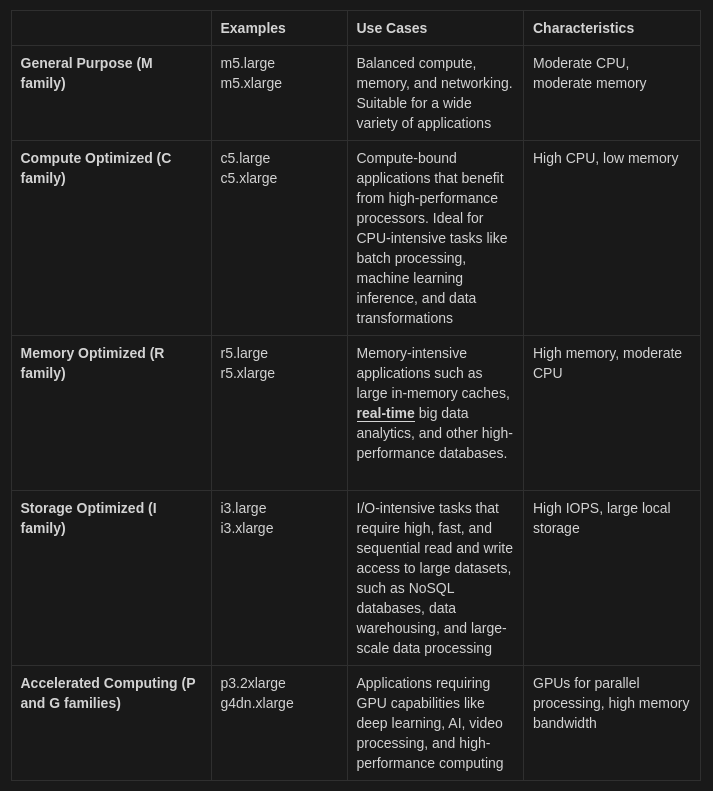
La première idée est sans aucun doute d’évaluer les types et familles d’instances. Pour cela, Databricks vous aide via l’interface et les possibilités sont larges :
- Optimisées pour le stockage, la mémoire, usage général, avec GPU
- Avec ou sans Delta cache accelerated (Databricks Runtime 14.2 et supérieur, la commande
CACHE SELECTest ignorée)
Pour les familles d’instances, résumons :
Si vous vous demandez à quelles instances EC2 elles correspondent, la console AWS est toujours un bon point de départ pour comparer les instances :
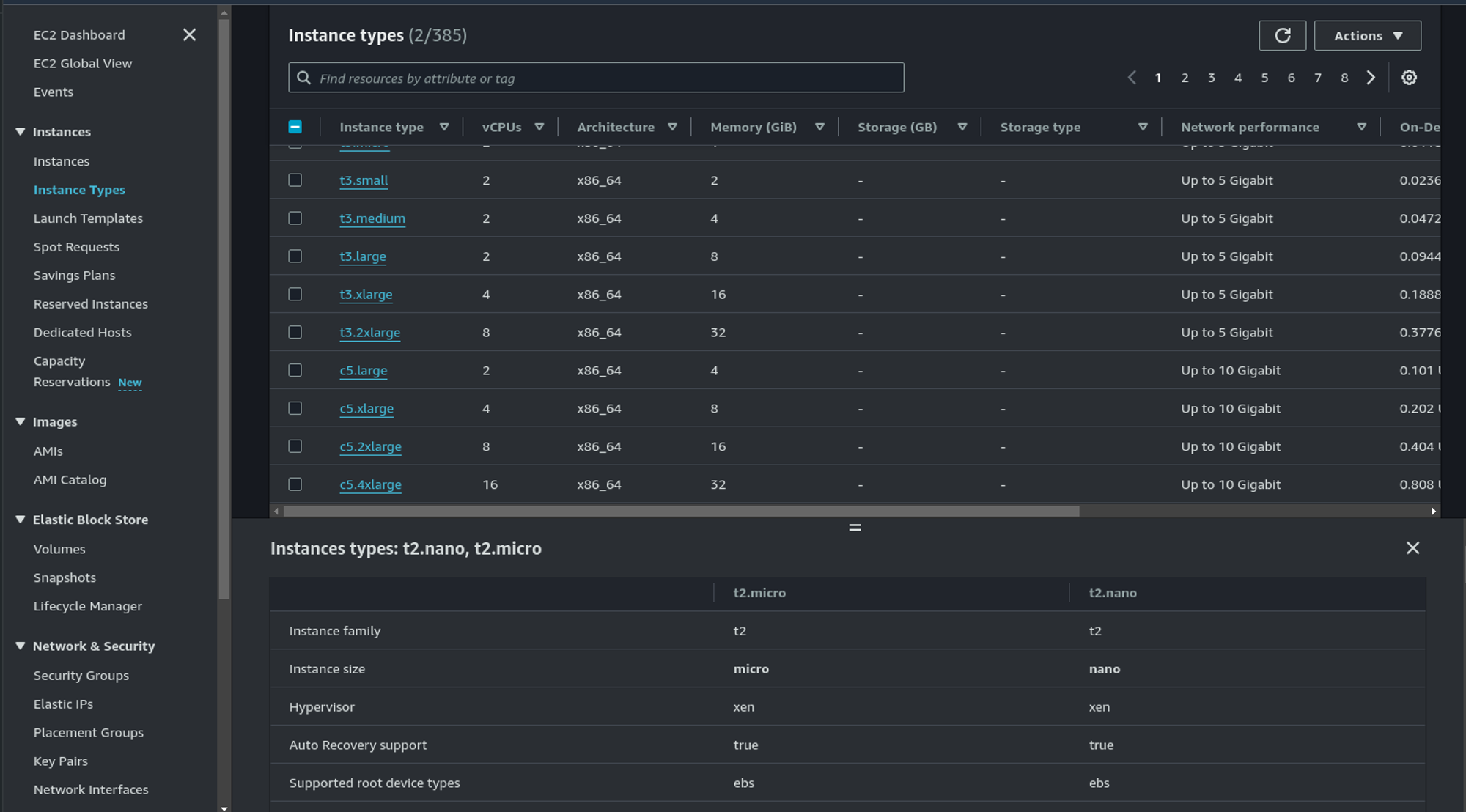
Et si vous vous demandez aussi ce que signifient toutes ces lettres, vous trouverez une explication rapide dans cet article.

Au-delà des considérations générales, le meilleur conseil est de surveiller votre charge de travail et d’observer comment les composants internes du cluster (mémoire et CPU) réagissent. Idem pour le dimensionnement du nœud driver.
Pour le Delta cache comme expliqué précédemment, si vous utilisez les runtimes les plus récents, ce n’est pas quelque chose sur lequel vous devez vous attarder. Et d’ailleurs, choisir le dernier runtime semble toujours apporter de bonnes nouvelles côté performances (mais vérifiez toujours que votre code tourne dessus).
Attention aussi aux instances Graviton, elles ne supportent pas certaines fonctionnalités.
Exploitez les capacités cloud
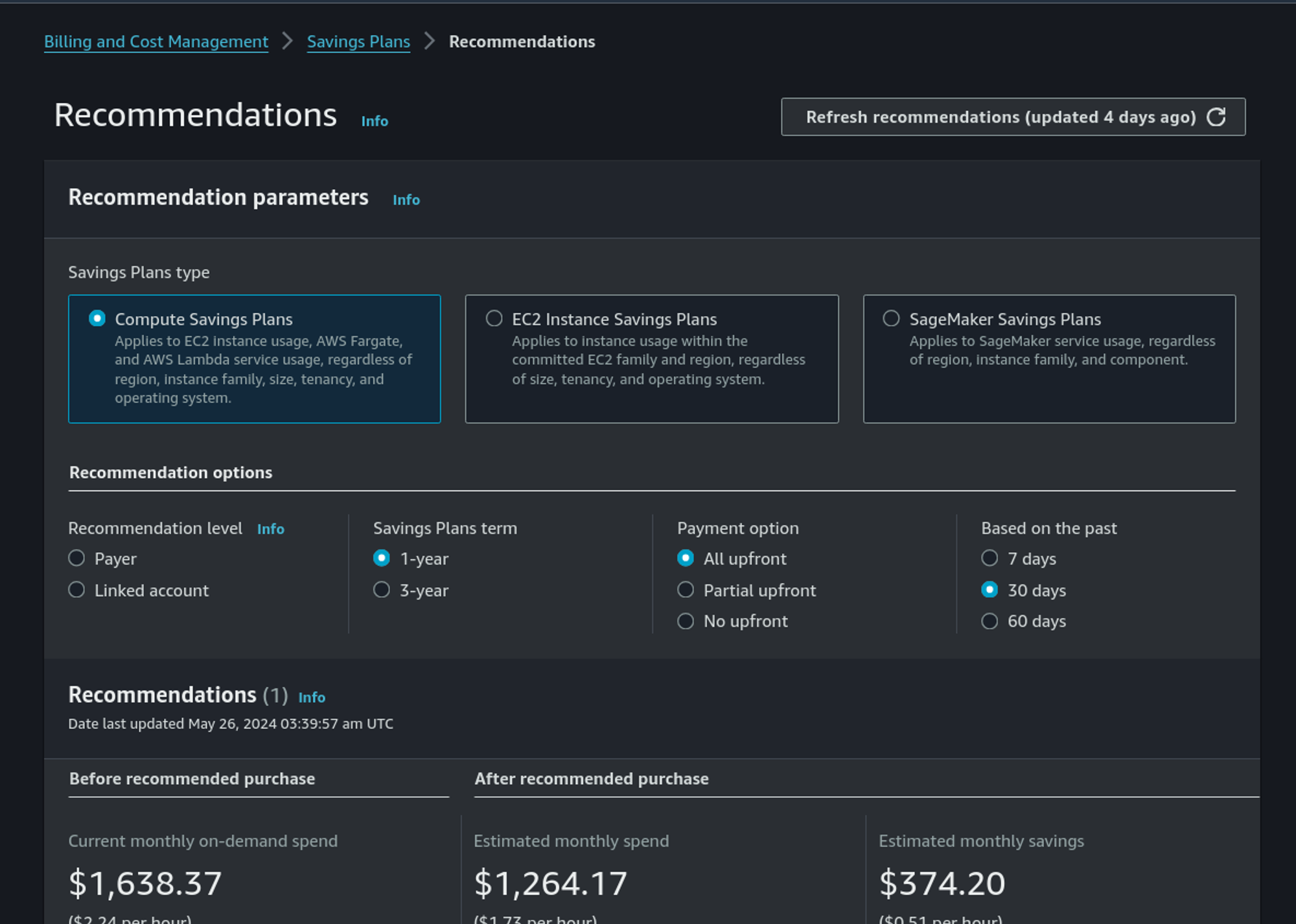
Sans rapport direct avec Databricks, les fournisseurs cloud offrent aussi des capacités spécifiques pour optimiser vos factures. Chez AWS, cela peut être des réductions via les Saving Plans (plus flexibles avec de plus grosses remises) et les Reserved Instances (pas la meilleure option).
C’est simplement un engagement de votre part envers AWS : vous engagez votre consommation sur une famille et en contrepartie, AWS vous accorde une remise. Et elle est plus importante si vous payez une partie ou la totalité d’avance (upfront).
AWS propose des recommandations automatiques basées sur votre consommation passée. C’est un bon point de départ :
Photon ou pas Photon ?
Dernier point et non des moindres, tel que défini par Databricks, Photon peut être vu comme une solution rentable.
Photon est un moteur de requêtes vectorisé haute performance natif Databricks qui exécute vos workloads SQL et appels d’API DataFrame plus rapidement afin de réduire le coût total par workload.
Certes, Photon est peut-être pour vous une évidence quand votre objectif est d’aller plus vite, comme avec un Job cluster pour obtenir vos résultats plus rapidement avant terminaison. Mais avez-vous vraiment fait le calcul ?
Car par défaut, Photon signifie payer le double. C’est aussi simple que ça. Mais est-ce que Photon divise aussi votre temps par deux ?
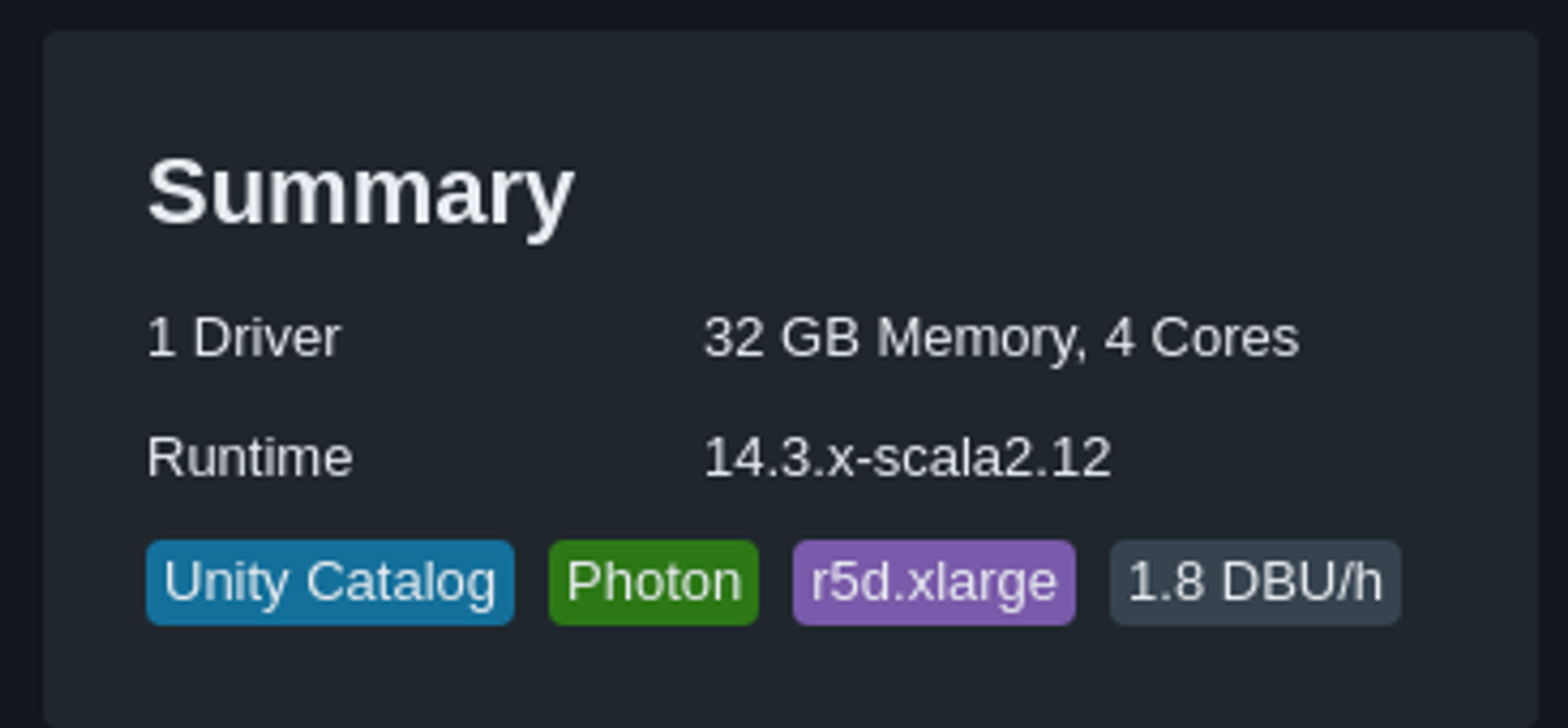
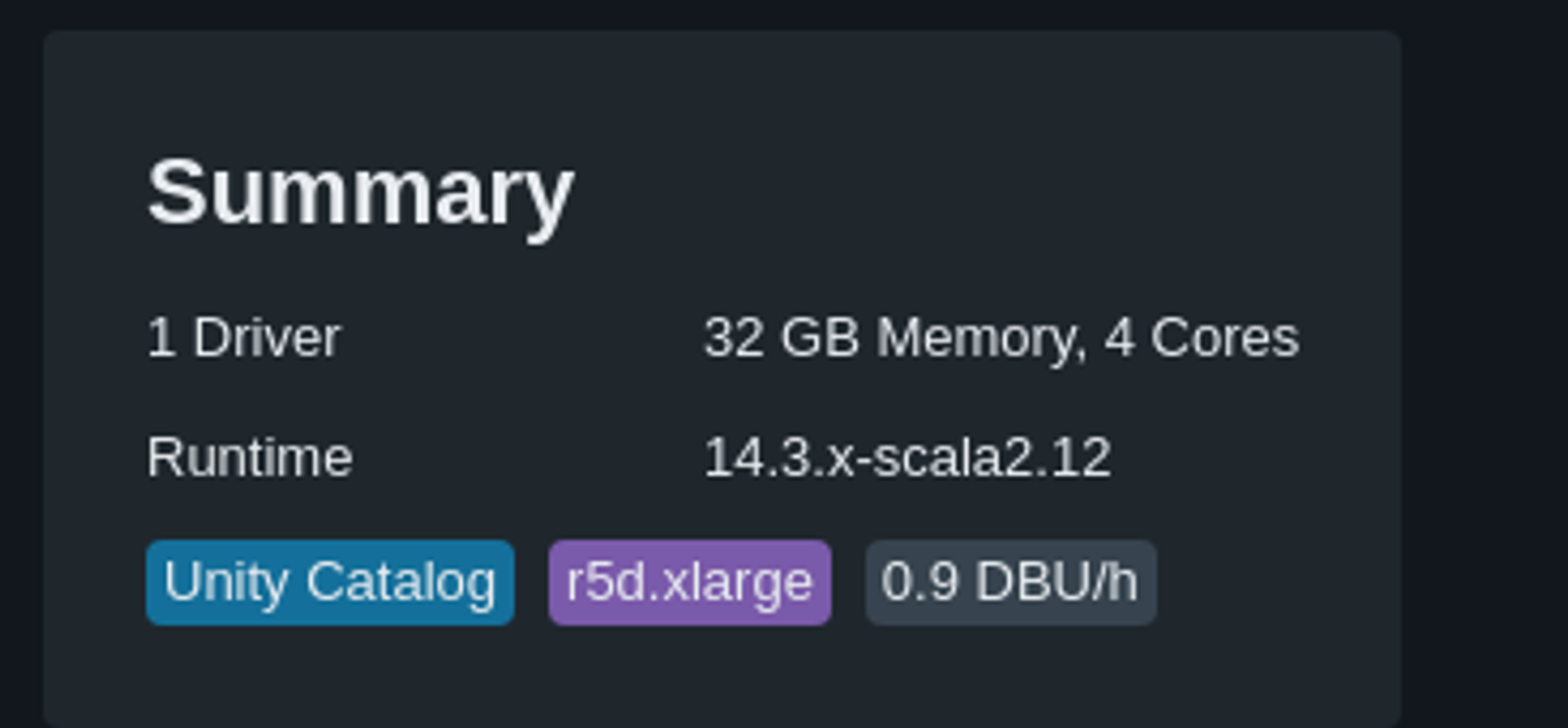
Ce n’est pas (encore) une conclusion
Ceci conclut notre discussion sur la gestion des coûts Databricks. Nous pouvons envisager de couvrir dans un prochain article des sujets tels que la configuration des jobs et clusters, l’auto-terminaison, les pool clusters, les fleet et spot instances, ainsi que les SQL warehouses.